金声玉亮2.0模型评测报告
客观题
OpenFinData是由东方财富与上海人工智能实验室联合发布的开源金融评测数据集。该数据集代表了最真实的产业场景需求,是目前场景最全、专业性最深的金融评测数据集。它基于东方财富实际金融业务的多样化丰富场景,旨在为金融科技领域的研究者和开发者提供一个高质量的数据资源。
C-Eval是全面的中文评估套件,旨在评估中国背景下基础模型的高级知识和推理能力。选取C-Eval 商业、金融等学科进行测试。
CMMLU 是一个全面的中文评估基准,专门用于评估语言模型在中文背景下的知识和推理能力。CMMLU 涵盖 67 个主题,从基础科目到高级专业水平。选取CMMLU 商业、金融等学科进行测试。
MMLU 是一种新的基准测试,旨在通过仅在零镜头和少镜头设置中评估模型来衡量预训练期间获得的知识。这使得基准更具挑战性,并且更类似于我们评估人类的方式。该基准测试涵盖 57 个学科。选取MMLU 商业、金融等学科进行测试。
GAOKAO-Bench是一个以中国高考题目为数据集,测评大模型语言理解能力、逻辑推理能力的测评框架,在中国,高考是标准化水平最高、综合性最强并且认可度最广的考试之一,借用高考的题目来评估大模型的能力。题集收集了2010-2022年全国高考卷的题目,其中包括1781道客观题和1030道主观题。
MBPP是Google-research发布的,该基准测试由大约 1,000 个众包的 Python 编程问题组成,旨在由入门级程序员解决,涵盖编程基础知识、标准库功能等。每个问题由任务描述、代码解决方案和 3 个自动化测试用例组成。
HumanEval由openai发布,它用于测量从文档字符串合成程序的功能正确性。它由 164 个原始编程问题组成,评估语言理解、算法和简单的数学,其中一些问题可与简单的软件面试问题相媲美。
评分规则:
选项:常见于分类任务,判断题以及选择题,目前这类问题的数据集占比最大,有 MMLU, CEval 数据集等等,评估标准一般使用准确率–ACCEvaluator。ACCEvaluator通过计算预测正确的样本数占总样本数的比例来评估模型的准确性,即正确预测的结果与实际结果相匹配的程度。
短语:常见于问答以及阅读理解任务,这类数据集主要包括 CLUE_CMRC, CLUE_DRCD, DROP 数据集等等,评估标准一般使用匹配率–EMEvaluator。EMEvaluator通过计算预测答案与参考答案完全匹配的比例来评估准确率,即预测答案必须与任一参考答案完全相同才被视为正确。
句子:常见于翻译以及生成伪代码、命令行任务中,主要包括 Flores, Summscreen, Govrepcrs, Iwdlt2017 数据集等等,评估标准一般使用 BLEU(Bilingual Evaluation Understudy)–BleuEvaluator。BLEU评估方法通过计算预测文本与参考文本之间的BLEU分数来衡量机器翻译的质量,其中BLEU分数是基于n-gram精确度和句子长度的 brevity penalty 计算得出的。
段落:常见于文本摘要生成的任务,常用的数据集主要包括 Lcsts, TruthfulQA, Xsum 数据集等等,评估标准一般使用 ROUGE(Recall-Oriented Understudy for Gisting Evaluation)–RougeEvaluator。RougeEvaluator通过计算预测摘要与参考摘要之间的ROUGE分数来评估自动文本摘要的质量,主要依据不同类型的n-gram重叠以及最长公共子序列来计算F1得分。
代码:常见于代码生成的任务,常用的数据集主要包括 Humaneval,MBPP 数据集等等,评估标准一般使用执行通过率以及 pass@k,目前 Opencompass 支持的有MBPPEvaluator、HumanEvalEvaluator。BPPEvaluator、HumanEvalEvaluator通过评估代码完成任务的正确性来评价模型生成的代码质量,具体是通过计算模型生成的代码解决方案在给定测试用例上的通过率来进行评估。
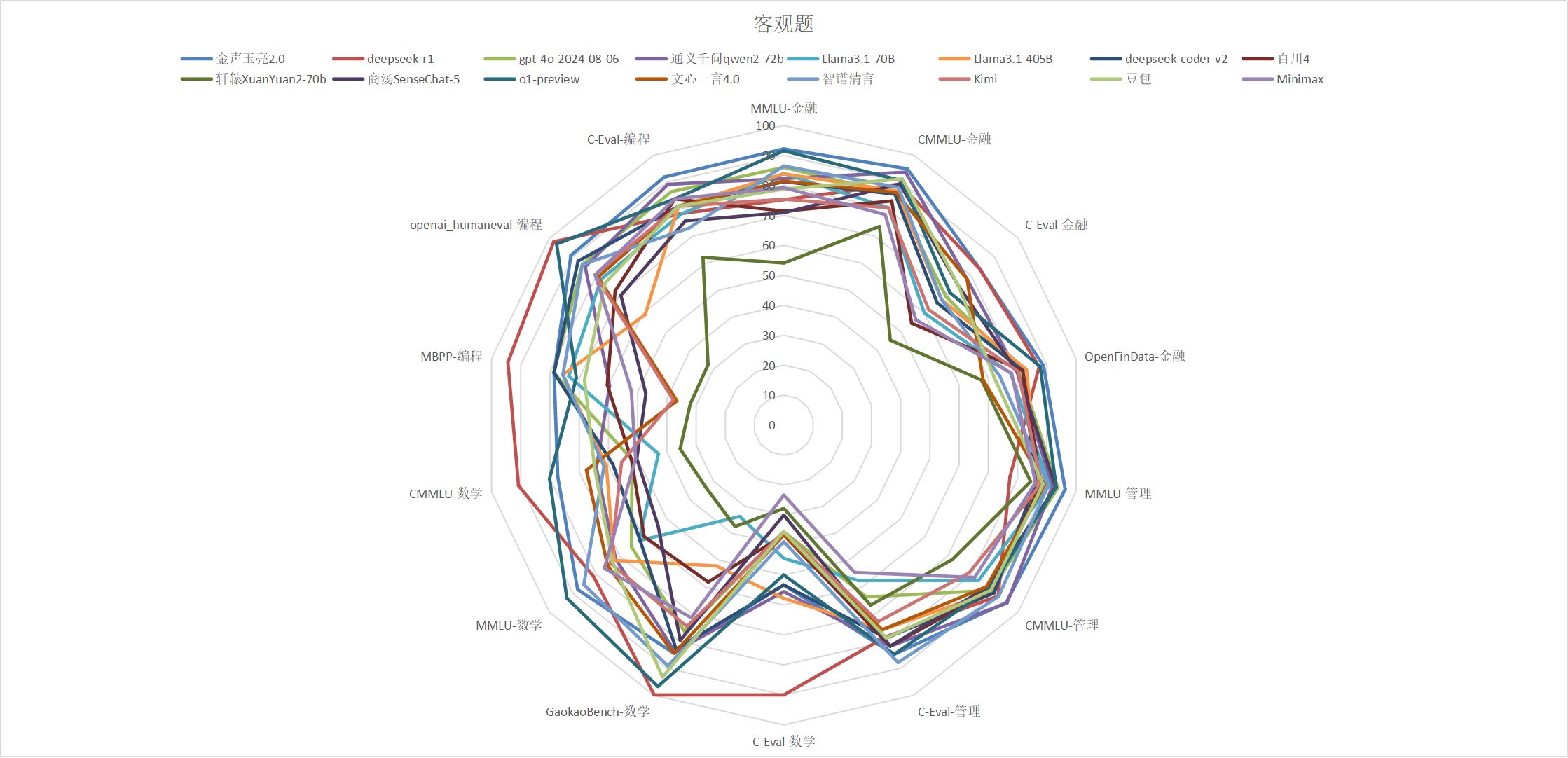
| 模型 |
MMLU-金融 |
CMMLU-金融 |
C-Eval-金融 |
OpenFinData-金融 |
MMLU-管理 |
CMMLU-管理 |
C-Eval-管理 |
C-Eval-数学 |
GaokaoBench-数学 |
MMLU-数学 |
CMMLU-数学 |
MBPP-编程 |
openai_humaneval编程 |
C-Eval-编程 |
| 金声玉亮2.0 |
92.20 |
94.97 |
83.64 |
88.89 |
96.29 |
94.92 |
84.85 |
53.33 |
84.49 |
87.97 |
77.35 |
78.60 |
90.85 |
91.89 |
| deepseek-r1 |
75.23 |
89.31 |
83.64 |
87.38 |
77.39 |
91.47 |
78.38 |
90.00 |
99.77 |
81.11 |
90.78 |
94.40 |
98.17 |
78.38 |
| deepseek-v3 |
35.79 |
89.94 |
70.91 |
80.43 |
89.77 |
9.77 |
63.64 |
50.00 |
87.73 |
48.21 |
70.34 |
79.60 |
85.37 |
78.38 |
| o1-preview |
91.57 |
90.57 |
70.91 |
87.78 |
93.22 |
87.70 |
84.85 |
50.00 |
96.76 |
92.58 |
80.16 |
71.00 |
96.95 |
83.78 |
| gpt-4o-2024-08-06 |
86.03 |
85.53 |
69.09 |
80.69 |
93.82 |
88.37 |
63.64 |
35.56 |
76.39 |
65.04 |
51.90 |
78.80 |
85.98 |
86.49 |
| 通义千问qwen2-72b |
82.29 |
93.71 |
78.18 |
79.79 |
91.88 |
95.24 |
81.82 |
55.56 |
83.80 |
71.71 |
64.13 |
59.60 |
84.76 |
89.19 |
| Llama3.1-70B |
84.00 |
80.50 |
60.00 |
77.67 |
90.87 |
83.10 |
57.58 |
44.44 |
33.80 |
61.75 |
42.89 |
73.60 |
78.05 |
78.38 |
| Llama3.1-405B |
83.86 |
86.79 |
67.27 |
83.07 |
86.81 |
89.17 |
75.76 |
57.78 |
52.08 |
72.37 |
60.72 |
75.60 |
59.15 |
81.08 |
| deepseek-coder-v2 |
81.26 |
85.53 |
65.45 |
81.83 |
86.19 |
89.76 |
78.79 |
53.33 |
82.87 |
61.37 |
58.52 |
78.60 |
87.80 |
81.08 |
| 百川4 |
71.40 |
83.02 |
54.55 |
81.77 |
88.02 |
88.45 |
81.82 |
36.67 |
58.10 |
59.59 |
52.10 |
60.40 |
71.95 |
83.78 |
| 轩辕XuanYuan2-70b |
54.12 |
73.58 |
45.45 |
67.66 |
84.46 |
71.90 |
66.67 |
27.78 |
37.50 |
33.27 |
35.47 |
32.00 |
32.32 |
62.16 |
| 商汤SenseChat-5 |
70.90 |
89.31 |
74.55 |
79.98 |
93.07 |
86.75 |
81.82 |
30.00 |
79.63 |
53.67 |
50.30 |
47.20 |
69.51 |
75.68 |
| 文心一言4.0 |
81.41 |
86.16 |
78.18 |
68.20 |
89.36 |
86.47 |
75.76 |
36.67 |
84.49 |
75.19 |
67.54 |
36.60 |
79.27 |
81.08 |
| 智谱清言 |
86.47 |
88.05 |
67.27 |
73.88 |
90.48 |
91.67 |
87.88 |
38.89 |
89.12 |
85.34 |
61.52 |
75.60 |
85.98 |
72.97 |
| Kimi |
75.39 |
80.50 |
61.82 |
80.25 |
88.02 |
79.05 |
72.73 |
35.56 |
74.54 |
73.97 |
55.51 |
37.80 |
80.49 |
81.08 |
| 豆包 |
78.76 |
91.19 |
74.55 |
71.97 |
88.72 |
88.37 |
78.79 |
35.56 |
93.29 |
73.12 |
64.73 |
68.20 |
76.22 |
81.08 |
| Minimax |
79.24 |
77.99 |
56.36 |
77.94 |
86.13 |
81.47 |
54.55 |
23.33 |
71.30 |
76.60 |
50.70 |
52.20 |
80.49 |
83.78 |
主观题
LiveBench:一个以测试集污染和客观评估为设计理念的基准LLMs。它具有以下属性:
LiveBench 旨在通过每月发布新问题以及根据最近发布的数据集、arXiv 论文、新闻文章和 IMDb 电影概要提出问题来限制潜在的数据集污染。
每个问题都有可验证的、客观的实况答案,允许准确、自动地对难题进行评分,而无需使用LLM裁判。
LiveBench目前包含6个类别的18个不同任务。
具体类别和任务如下:
数学:包括过去12个月的高中数学竞赛问题(如AMC12、AIME、USAMO、IMO、SMC)以及更难版本的AMP问题。
编码:包括通过LiveCodeBench从Leetcode和AtCoder生成的代码问题,以及一个新的代码完成任务。
推理:涵盖了Big-Bench Hard中的Web of Lies的更难版本、bAbI中的PathFinding的更难版本,以及Zebra Puzzles。
语言理解:包含三个任务:Connection单词谜题、拼写修正任务和电影梗概重组任务,均来自IMDb和Wikipedia上的最新电影。
指令执行:包括四个任务,要求释义、简化、总结或根据《卫报》的最新新闻文章编写故事,并遵循一到多个指令或在响应中加入特定元素。
数据分析:包括使用Kaggle和Socrata最新数据集的三个任务:表格转换(在JSON、JSONL、Markdown、CSV、TSV和HTML之间)、预测哪些列可以用来连接两个表格,以及预测数据列的正确类型注释。
评分规则:
LiveBench 采用客观的真实判断(Objective ground-truth judging)来评估每个问题。客观的真实判断是将 LLM预先确定的真值答案进行比较。这种方法非常有用,因为根据时间和成本对输出进行评分是微不足道的。此外,它避免了LLM 作为裁判和人工评判在判断中的偏差、错误和可变性方面的弱点。客观的真实判断的一个弱点是某些类型的问题没有真实答案,例如“写一本夏威夷旅游指南”。但是,虽然这限制了可以评估的问题类型,但不会影响可以以这种方式判断的问题的评估有效性。客观的真实判断包括通过正则表达式提取输出、表格格式转换、数学表达式解析、文本匹配等,将LLM输出与标准答案进行对比,计算准确率、召回率、F1得分或使用Levenshtein距离等相似度测量,以评估模型的正确性和一致性。
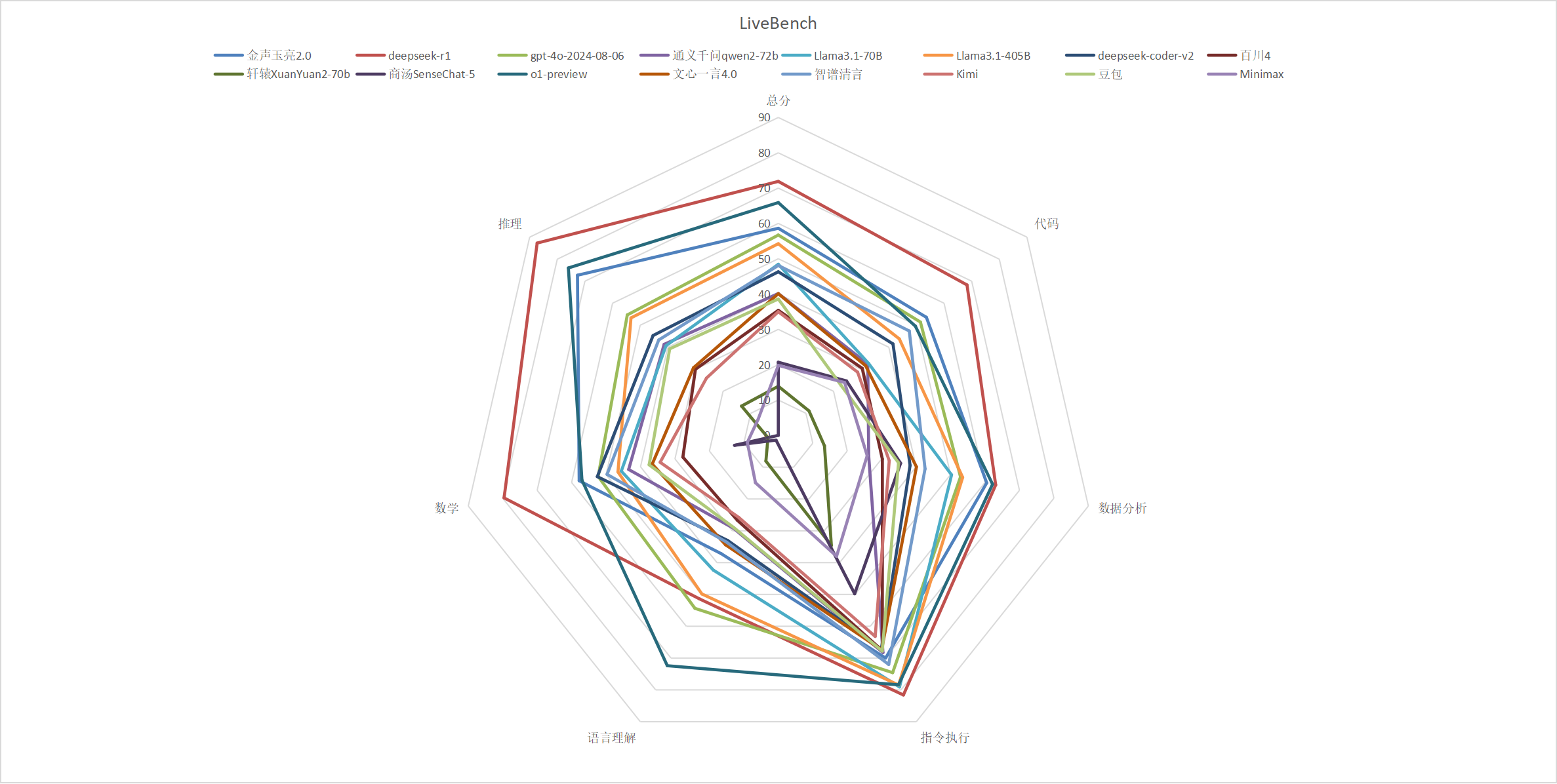
| 模型 |
总分 |
代码 |
数据分析 |
指令执行 |
语言理解 |
数学 |
推理 |
| 金声玉亮2.0 |
58.63 |
53.60 |
60.50 |
70.00 |
37.20 |
57.80 |
72.70 |
| deepseek-r1 |
71.90 |
68.30 |
63.10 |
81.60 |
51.40 |
79.60 |
87.30 |
| deepseek-v3 |
48.40 |
65.20 |
48.50 |
81.10 |
43.20 |
31.10 |
21.30 |
| o1-preview |
65.90 |
49.60 |
62.20 |
78.40 |
72.40 |
57.00 |
76.00 |
| gpt-4o-2024-08-06 |
56.71 |
51.44 |
52.89 |
74.58 |
54.37 |
52.29 |
54.67 |
| 通义千问qwen2-72b |
40.15 |
32.38 |
26.24 |
68.27 |
29.21 |
43.44 |
41.33 |
| Llama3.1-70B |
48.44 |
32.67 |
50.29 |
79.08 |
42.36 |
45.58 |
40.67 |
| Llama3.1-405B |
54.25 |
43.80 |
53.51 |
78.47 |
49.85 |
46.55 |
53.33 |
| deepseek-coder-v2 |
46.31 |
41.51 |
38.25 |
67.18 |
33.04 |
52.54 |
45.33 |
| 百川4 |
35.40 |
30.40 |
30.20 |
67.50 |
26.70 |
27.70 |
30.00 |
| 轩辕XuanYuan2-70b |
13.90 |
11.10 |
13.40 |
34.60 |
8.10 |
3.00 |
13.30 |
| 商汤SenseChat-5 |
20.70 |
24.70 |
35.50 |
49.80 |
1.50 |
12.70 |
0.00 |
| 文心一言4.0 |
40.10 |
31.60 |
40.10 |
67.40 |
34.40 |
36.60 |
30.70 |
| 智谱清言 |
48.10 |
47.40 |
42.60 |
72.00 |
33.60 |
49.70 |
43.30 |
| Kimi |
35.00 |
28.70 |
32.20 |
63.20 |
25.80 |
34.30 |
26.00 |
| 豆包 |
38.60 |
22.70 |
34.90 |
67.80 |
29.00 |
37.50 |
39.30 |
| Minimax |
19.80 |
24.00 |
25.80 |
38.00 |
14.90 |
9.00 |
7.30 |
汇集了一系列由实际用户在金融、商业场景中提出的、具有代表性和挑战性的问题。这些问题涵盖涵盖但不限于市场趋势分析、投资策略制定、风险控制措施、企业财务健康状况评估、商业模型创新等方面。这些问题不仅来源于金融分析师、投资者、企业家等专业人士的实际工作经历,还包括了普通消费者在日常财务管理过程中可能遇到的具体挑战和实践应用。
评分标准方面,采用GPT-4o作为独立裁判来评估针对上述问题的不同模型生成的答案。GPT-4o将根据推理能力、时效性、准确性、全面性、逻辑性、实用性、相关性、专业性等多维度对答案进行综合评价,并据此给出评分。这一标准化的评价体系有助于客观地衡量各模型在解决金融与商业问题上的能力。
具体打分方式:由GPT-4o给出排序,每道题排名第一得10分,第二名得9.58,第三名得9.16,第四名得8.75,第五名得8.33,第六名得7.91,第七名得7.5,第八名得7.08,第九名得6.67,第十名得6.25分,第十一名得5.83分,第十二名得5.41分,第十三名得5分。最后计算各个大模型的平均得分。
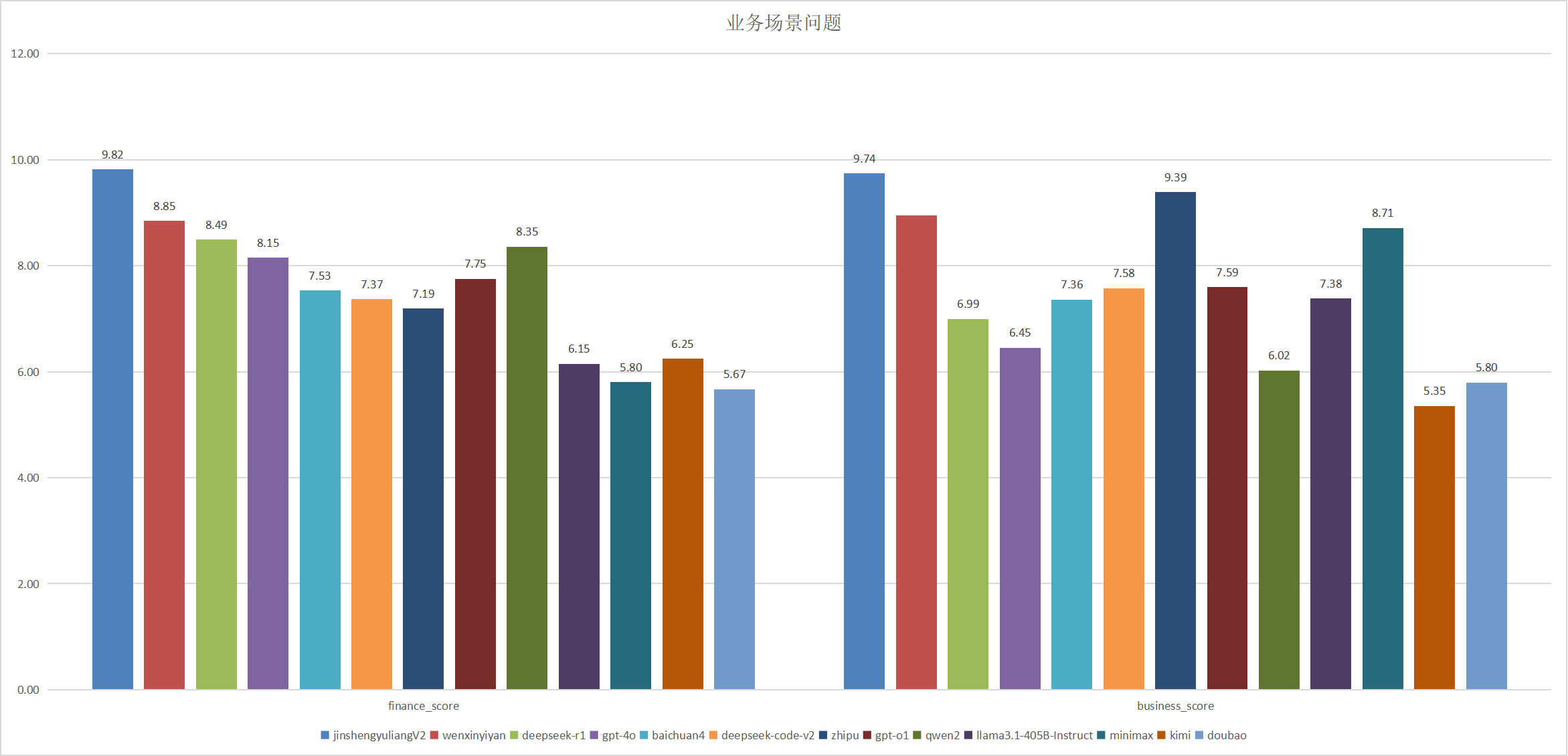
| 模型 |
金融 |
商业 |
| 金声玉亮2.0 |
9.83 |
9.58 |
| deepseek-r1 |
8.92 |
9.45 |
| deepseek-v3 |
8.23 |
8.77 |
| o1-preview |
5.83 |
8.84 |
| gpt-4o-2024-08-06 |
6.92 |
8.54 |
| 文心一言4.0 |
9.27 |
7.59 |
| 通义千问qwen2-72b |
7.52 |
6.72 |
| deepseek-coder-v2 |
6.82 |
6.58 |
| 百川4 |
6.89 |
6.33 |
| 智谱清言 |
8.73 |
6.90 |
| Llama3.1-405B |
7.73 |
7.34 |
| Kimi |
5.59 |
5.30 |
| Minimax |
6.15 |
5.98 |
| 豆包 |
6.41 |
6.88 |
下图展示各个模型答案排名第一的百分比
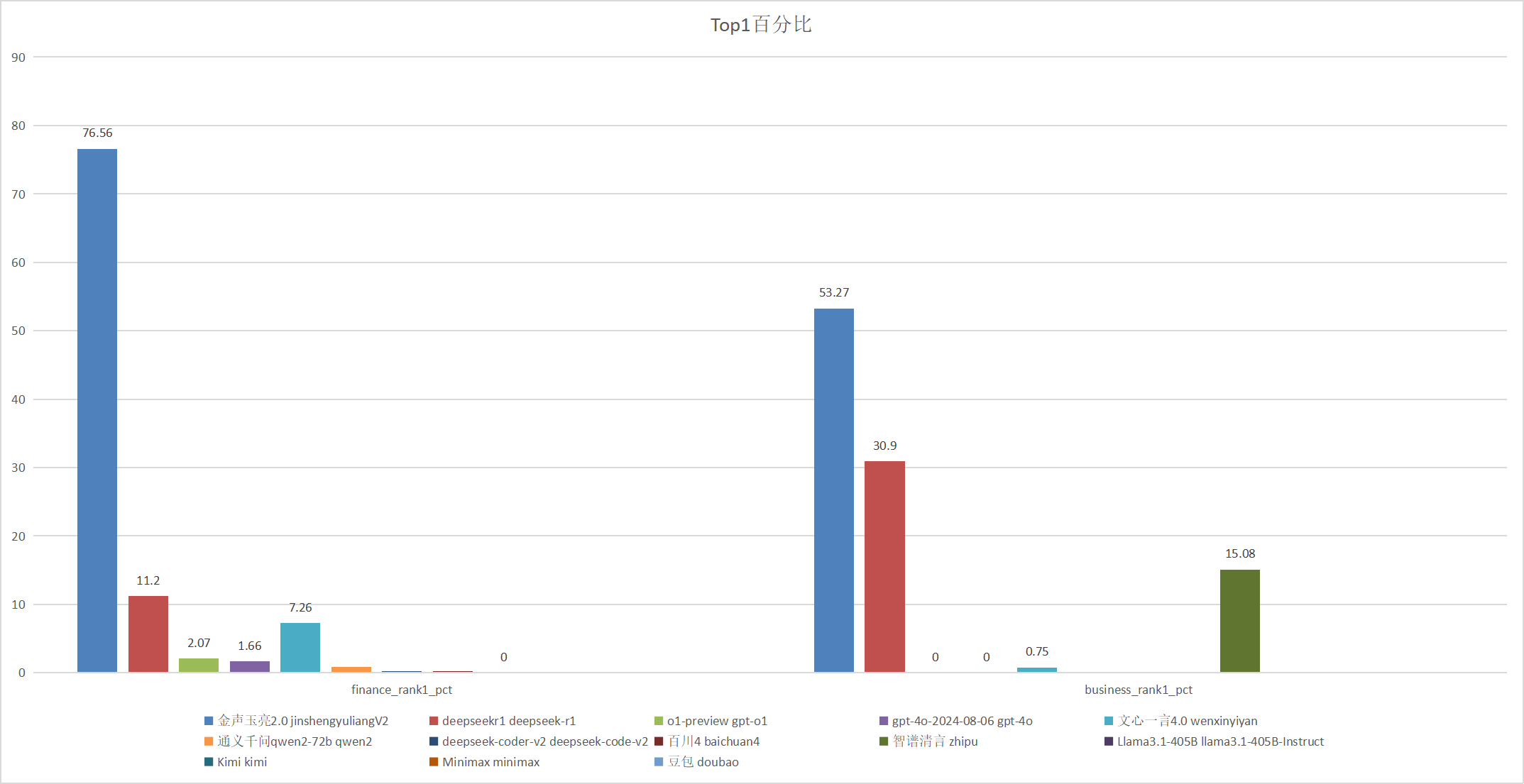
| 模型 |
金融 |
商业 |
| 金声玉亮2.0 |
76.06 |
34.13 |
| deepseek-r1 |
10.51 |
47.88 |
| deepseek-v3 |
0.67 |
4.50 |
| o1-preview |
0.00 |
11.90 |
| gpt-4o-2024-08-06 |
0.00 |
1.59 |
| 文心一言4.0 |
9.84 |
0.00 |
| 通义千问qwen2-72b |
0.22 |
0.00 |
| deepseek-coder-v2 |
0.00 |
0.00 |
| 百川4 |
0.00 |
0.00 |
| 智谱清言 |
1.57 |
0.00 |
| Llama3.1-405B |
1.12 |
0.00 |
| Kimi |
0.00 |
0.00 |
| Minimax |
0.00 |
0.00 |
| 豆包 |
0.00 |
0.00 |